SepEx: Visual Analysis of Class Separation Measures
EuroVA 2020 (to appear), co-located with EuroVis and EuroGraphicsAbstract | Paper | Video Presentation | Figures | Data | Open Source | Supplemental Material
SepEx on OSF.io
Abstract
Class separation is an important concept in machine learning and visual analytics. However, the comparison of class separation for datasets with varying dimensionality is non-trivial, given a) the various possible structural characteristics of datasets and b) the plethora of separation measures that exist. Building upon recent findings in visualization research about the qualitative and quantitative evaluation of class separation for 2D dimensionally reduced data using scatterplots, this research addresses the visual analysis of class separation measures for high-dimensional data. We present SepEx, an interactive visualization approach for the assessment and comparison of class separation measures for multiple datasets. SepEx supports analysts with the comparison of multiple separation measures over many high-dimensional datasets, the effect of dimensionality reduction on measure outputs by supporting nD to 2D comparison, and the comparison of the effect of different dimensionality reduction methods on measure outputs. We demonstrate SepEx in a scenario on 100 two-class 5D datasets with a linearly increasing amount of separation between the classes, illustrating both similarities and nonlinearities across 11 measures.Paper
Video Presentation
We demonstrate SepEx in a 13-minute video presentation, as presented at the EuroVA 2020 (virtual conference due to COVID-19).
Figures
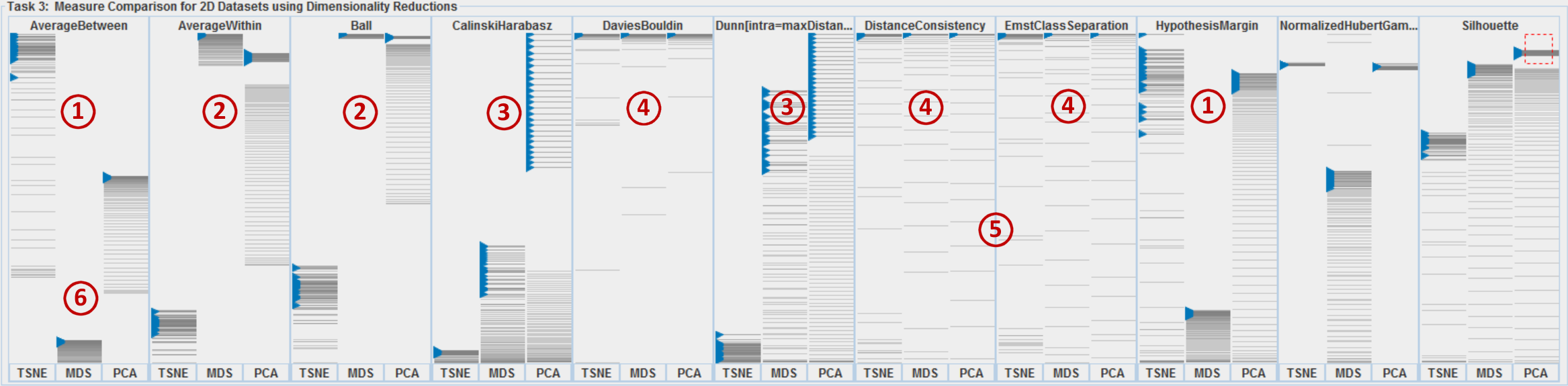
Data
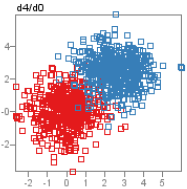
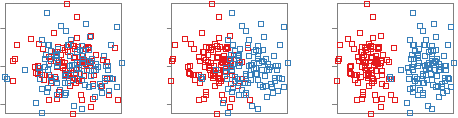
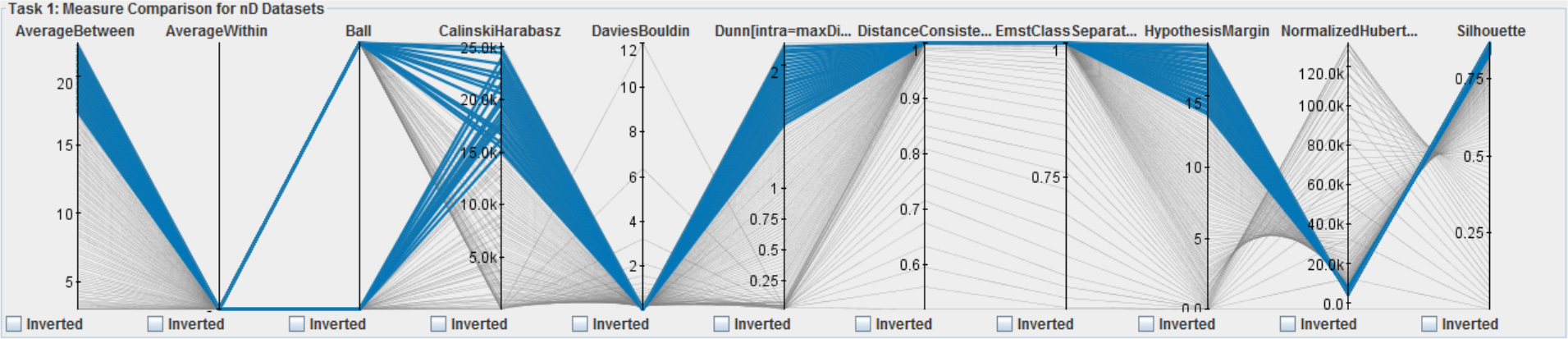
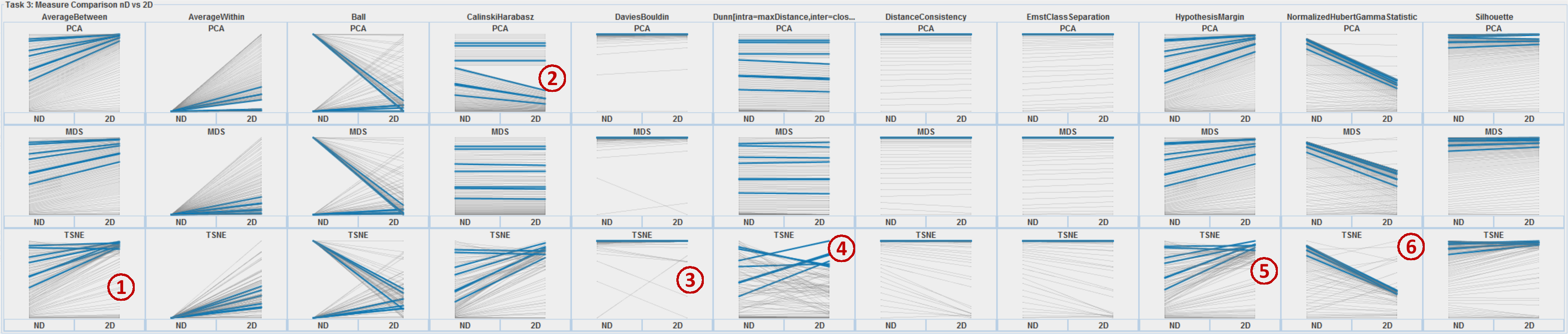
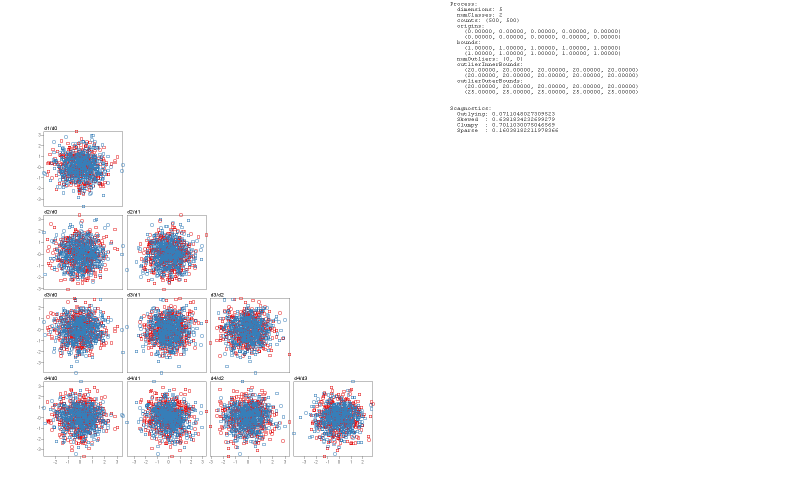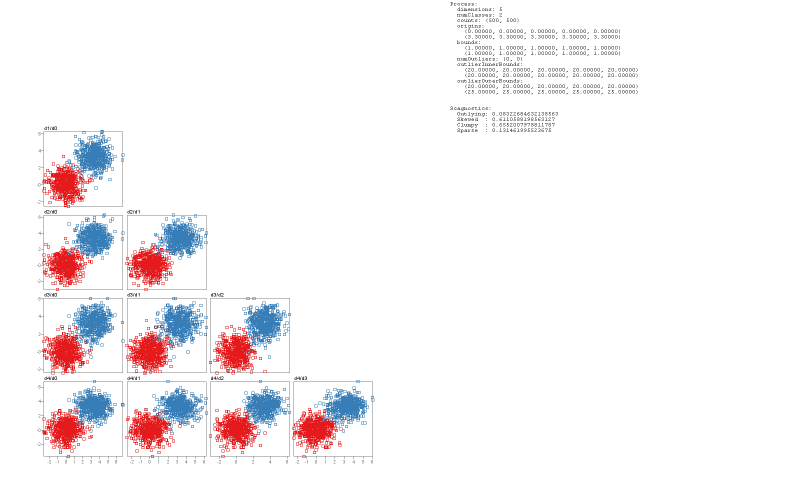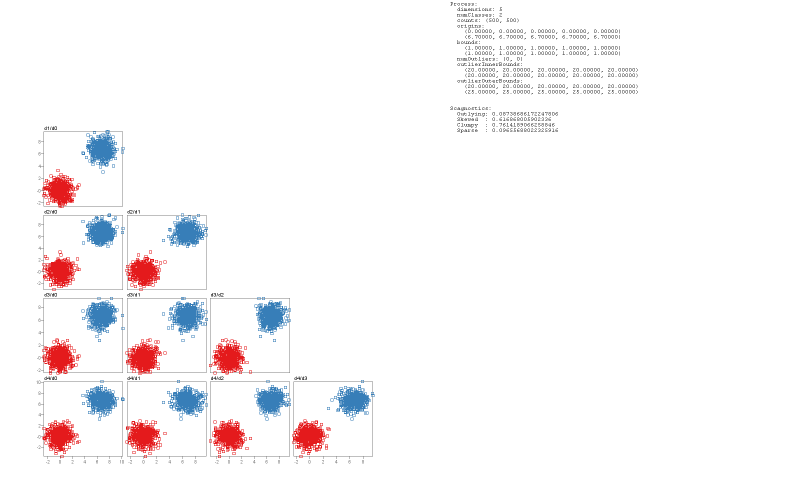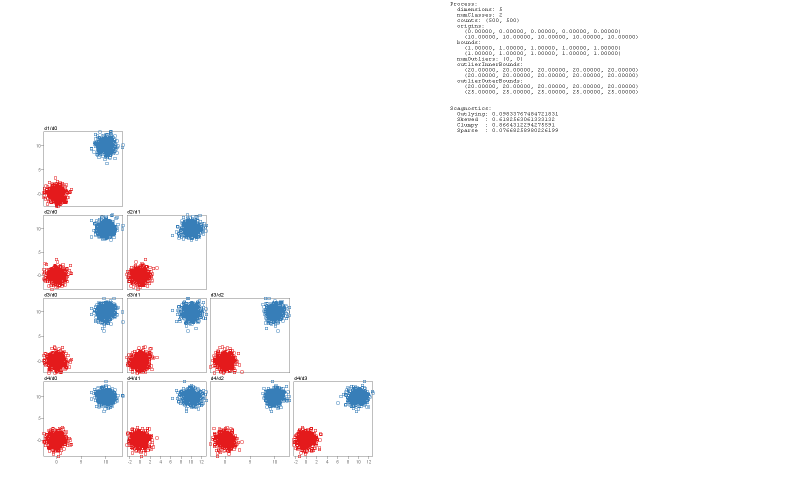
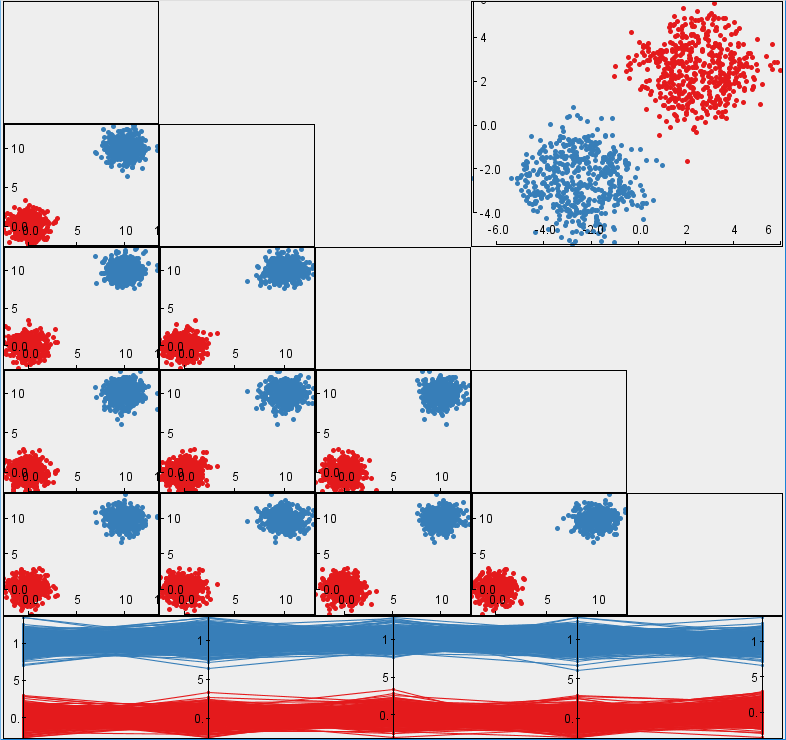
We demonstrate how SepEx can be used in a sensitivity analysis scenario. Our goals thereby are to validate SepEx by primarily studying measure characteristics, and excluding effects stemming from (uncontrolled) dataset characteristics (see future work). Therefore, we employ 100 synthetic datasets, all with 5 dimensions, 1000 instances, and two classes. The datasets differ by their class separation from overplotted to separated (cf. Figure 1, more details in the supplemental material). We analyze how consistent the estimates of 11 separation measures are for the differently separated datasets. The results of 3 DR methods further allow the analysis of consistency between nD and 2D data representations, followed the visual analysis of 11 measures applied on the different DR-reduced 2D datasets.- Dataset Download from here
- Dataset Download from OSF.io
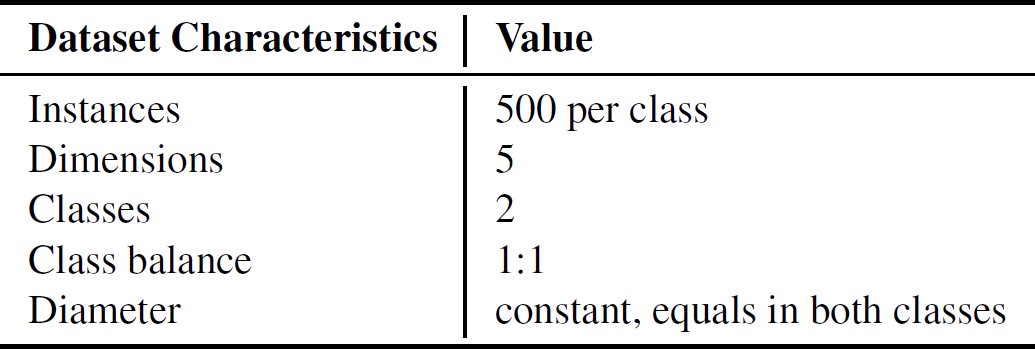
Open Source
We are planning to extend the SepEx approach and publish an extended version in a Journal. Along these lines, we also aim at providing an executable prototype to enable users assess separation measures by themselves. So far, we list the primary open source libraries used to build SepEx:- Complex Data Object - a data science library for multivariate data
- DMandMD - a data mining and machine learning library for multivariate data
- infoVis - a information visualization library
Supplemental Material
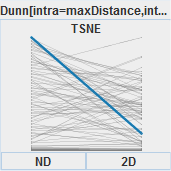
In the three sections of the supplemental materials document, we extend the degree to which details could be given in the manuscript. The first section describes all characteristics of the set of datasets that was used in the usage scenario. To do so, we also included additional figures showing sample datasets in detail. The second section shows screenshots of the entire system for every state and interface (cut) which made it into the paper. With this additional context (multiple linked views), we also add more findings we made during analyses. The third section provides details about the analysis of TSNE inconsistencies, including figures of selected datasets which have been dimensionality-reduced.Last modified: Feb 05, 2021